Fonte das tabelas: Livro: Química Analítica (Skoog)
Não podemos medir dados de toda uma população, então utilizamos uma amostra (uma parte da população) para representar uma população. Então, toda a nossa análise estatística é feita na amostra para tentar inferir informações de toda uma população.
A média (x) resume todos os dados de uma amostra coletados por uma mesma técnica. Assim, a média é a soma de todos os dados dividido pelo número de dados coletados. Entretanto, a média é apenas um número que tem uma relação com os vários números que você coletou da amostra. Dessa forma, se na coleta A os dados foram 5, 15, 20 ena coleta B os dados foram 13, 15, 17. Em ambas as coletas a média é 15, entretanto na coleta A, os dados estão variando 5 pontos para mais e 5 pontos para menos. Já a coleta B os dados variam apenas 2 pontos para mais e para menos. Então, não basta apenas dizer que a média 15 representa os dados. Precisamos também dizer o quanto que esses dados estão próximos. A grandeza que indica o quão próximo os dados estão da média é o desvio padrão, ou seja, o desvio da média. O desvio padrão de uma amostra é representado pela letra "s", o desvio padrão de uma população é representado pela letra grega sigma (σ).
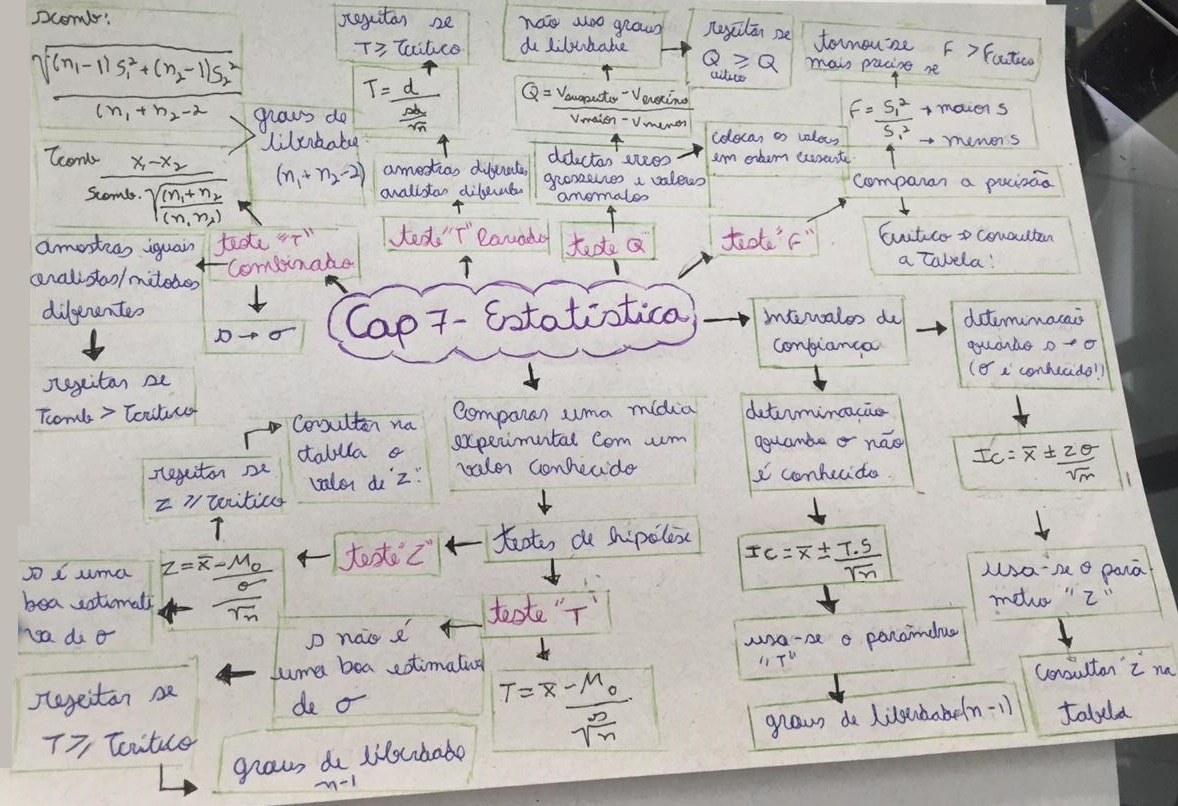
Teste de Hipótese
Testa se a diferença entre 2 resultados é significativa, ou se ela é simplesmente uma manifestação de variações aleatórias.
Comparação: média com valor verdadeiro, média com valor previsto, média ou desvio padrão de dois ou mais conjuntos de dados.
Hipótese nula: os valores são estatisticamente iguais, com tanto por cento de confiança.
Hipótese alternativa: os valores são estatisticamente diferentes, com tanto por cento de confiança.
Nível de confiança (NC) é a probabilidade de que a média verdadeira esteja localizada em um certo intervalo.
Nível de significância é a probabilidade de um resultado estar fora do intervalo de confiança.
Teste Z para grandes amostras.
Intervalo de Confiança: correlaciona o valor coletado com o valor verdadeiro existente em uma população. Indica o quanto que a média encontrada pela sua amostra representa a média da população.
Ao tirarmos a média de uma amostra, deve-se relatar o intervalo de confiança. Este intervalo de confiança indica a probabilidade do valor verdadeiro da média da população estar dentro daquele intervalo obtido a partir da amostra. Geralmente, utiliza-se 95% de confiança.
Este valor verdadeiro, também conhecido como valor real, é o valor tabelado, ou o valor aceito cientificamente como o correto para aquela situação. Geralmente ele já foi testado muitas vezes por diversos métodos diferentes e ficou conhecido como o valor de referência para aquilo que se está estudando. É importante ressaltar que o valor verdadeiro mesmo muitas vezes não pode ser acessado e geralmente usamos estimativas do valor verdadeiro. Assim, torna-se necessário estimar o intervalo de confiança que temos em uma população:
μ = x ±zσ/√N : intervalo de confiança de que a média de uma população está próxima à média do valor verdadeiro.
μ: intervalo de confiança
x: média.
z: parâmetro estatístico populacional (um número relacionado à probabilidade de que o valor encontrado em uma amostra grande ou em uma população represente o valor verdadeiro)
σ: sigma é desvio padrão populacional (indica quão longe da média estão os valores encontrados)
N: número de dados coletados.

Entretanto, geralmente não temos amostras tão grandes que possam se assemelhar à população, então, na prática costumamos usar dados de uma amostra, que irá representar a população:
Nesse sentido, para a amostra usaremos o "t" como parâmetro estatístico em vez de usar o "z" e para o desvio padrão da amostra usaremos o "s" em vez do "σ".
μ = x ±ts/√N: intervalo de confiança de que a média de uma amostra está próxima à média do valor verdadeiro.
μ: intervalo de confiança
x: média
t: parâmetro estatístico amostral (um número relacionado à probabilidade de que o valor encontrado na amostra represente o valor verdadeiro conhecido)
s: desvio padrão amostral (indica quão longe da média estão os valores encontrados na amostra)
N: número de dados coletados.

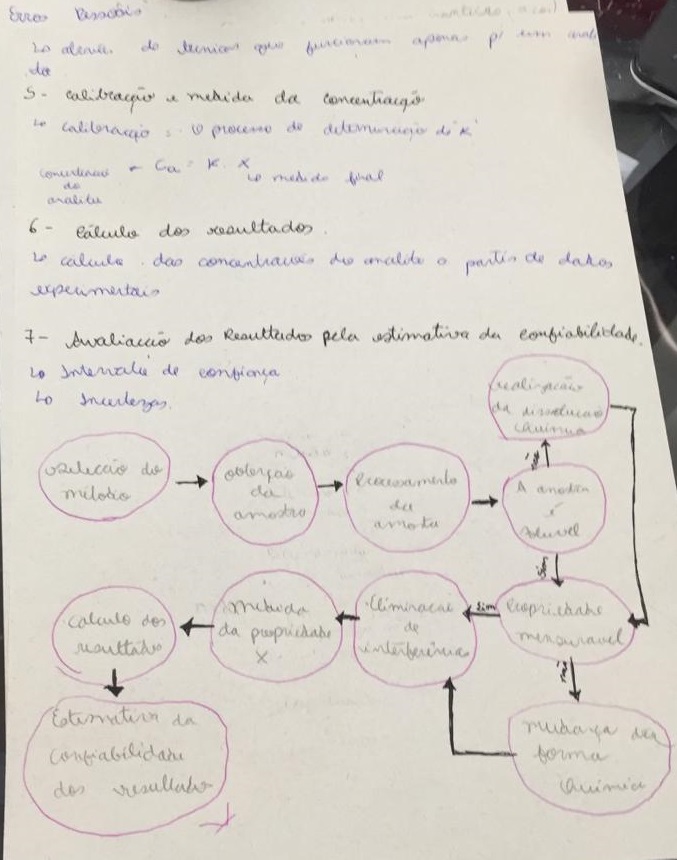
Quando fazemos pesquisas, buscamos ter os dados mais exatos (próximos do valor verdadeiro) possíveis e o mais precisos (próximos entre si) o possível. Entretanto, erros pessoais (exemplo:leitura errada da balança, leitura errada do menisco, lavagem da vidraria), erros instrumentais (exemplo: calibragem da balança, precisão dos aparelhos usados) e erros de método (exemplo: escolha do método utilizado, qualidade e estocagem de reagentes, especificidade de reagentes, limitações das técnicas utilizadas, falha na escolha de solução padrão) afetam os dados coletados.
Existem diversas fontes de erros quando realizamos pesquisas. Estes erros podem ser sistemáticos (exemplo: erro de calibração da balança) e deslocar todos os dados em uma direção, afetando a exatidão dos resultados ou aleatórios e afetar a precisão dos resultados, fazendo com que os dados fiquem dispersos e longe da média.

Erros sistemáticos: afetam a exatidão dos resultados e podem ser mensurados e reduzidos.
Tipos de erros sistemáticos: Instrumentais (falha em equipamentos utilizados, calibração), métodos (comportamento químico não ideal de reagentes e reações: lento, incompleto, produtos instáveis, reagentes não específicos), pessoais (falha de uma pessoa ao realizar uma prática laboratorial, leitura de resultado dependente da opinião de cada pessoa).
Detecção de erros sistemáticos constantes: calibração de equipamentos, checagem de medidas e anotações, utilização de materiais padrão de referência, análise por diferentes métodos analíticos, amostras do mesmo material analisados por diferentes pessoas, determinação do branco analítico (reagentes e solventes sem o analito).
Detecção de erros sistemáticos proporcionais: depende da concentração.
-------------------------------------------------------------------
Para checar a precisão entre dois grupos de dados deve-se usar a fórmula do teste F que é o quadrado do maior desvio padrão dividido pelo quadrado do menor desvio padrão, e comparar o F encontrado com o F tabelado para aquela precisão desejada (exemplo, 95% de confiança).
Para encontrar o valor de F na tabela (Fcrítico) basta relacionar o número de graus de liberdade do grupo que tem o maior desvio padrão (numerador) com o número de graus de liberdade da amostra que tem o menor desvio padrão (denominador).

Se o valor de F encontrado com a fórmula for menor que o valor de F encontrado na tabela (Fcrítico), não há diferença entre os dois grupos em relação à dispersão dos resultados. Se o F encontrado for maior que o tabelado (Fcrítico), há diferença entre os dois grupos quanto à dispersão.
-------------------------------------------------------------------
Para checar a exatidão dos resultados quanto a um valor tabelado de referência, também chamado como valor real ou verdadeiro, usa-se o teste t.
O teste t compara duas médias em relação ao desvio padrão.
A fórmula do teste t combinado deve ser usado quando vamos usar o teste t para comparar dados obtidos por duas técnicas diferentes e verificar se elas indicam a mesma coisa (conceito), já que estão medindo a mesma coisa (grandeza).
A fórmula do teste t pareado deve ser usada quando temos vários grupos sendo medidos por duas técnicas e queremos saber se essas técnicas tem um mesmo resultado se estão medindo a mesma coisa (exemplo: taxa de glicose, distância, tempo, agressividade, eficiência...).
Após encontrarmos o t da amostra devemos compará-lo com o t da tabela (tcrítico), que indica o máximo valor aceito para se considerar que o valor encontrado na amostra é igual ao valor verdadeiro. Se o t encontrado for menor que o tcrítico o resultado encontrado na amostra é exato em relação ao valor verdadeiro. Se o t encontrado for maior que o t crítico, a amostra ERRO.

Para detectar erros grotescos usamos o Teste Q, que identifica outliers, ou seja, valores muito longe dos outros dados. Quando esses erros grotescos acontecem, o pesquisador deve checar os dados e procedimentos realizados para tentar identificar o que gerou esse dado fora da linha. O grande problema desses valores muito longe do resto dos dados é que ele altera muito a média e o desvio padrão, fazendo com que estes não representem os dados como um todo. É muito importante pensar bem no que será feito com esses dados. Alguns pesquisadores simplesmente retiram esse valor, mas caso isso seja feito, é importante que seja relatado o que foi feito e porque. Outros pesquisadores colocam esses dados na extremidade do conjunto de dados, para reduzir o efeito do outlier, mas ainda assim haver o desvio da média. Assim, é importante pensar bem no que fazer com esse outlier e sempre relatar o que foi feito, justificando a decisão tomada.


Mapas mentais: fonte Ana Carollina.







Nenhum comentário:
Postar um comentário